
Recently, unconditional GAN models are divided into two main categories.
2D GANs have achieved photorealism and offer diverse options to control semantic attributes in generation or editing.
However, they lack 3D understanding in generation process. Existing editing models allow implicit pose control.
Recently proposed 3D-aware GANs have tackled the multi-view consistency problem and achieved (explicit) 3D controllability.
Although they have shown results of style mixing or interpolation, 3D GANs struggle to disentangle and control the semantic attributes.
Over the years, 2D GANs have achieved great successes in photorealistic portrait generation. However, they lack 3D understanding in the generation process, thus they suffer from multi-view inconsistency problem. To alleviate the issue, many 3D-aware GANs have been proposed and shown notable results, but 3D GANs struggle with editing semantic attributes. The controllability and interpretability of 3D GANs have not been much explored. In this work, we propose two solutions to overcome these weaknesses of 2D GANs and 3D-aware GANs. We first introduce a novel 3D-aware GAN, SURF-GAN, which is capable of discovering semantic attributes during training and controlling them in an unsupervised manner. After that, we inject the prior of SURF-GAN into StyleGAN to obtain a high-fidelity 3D-controllable generator. Unlike existing latent-based methods allowing implicit pose control, the proposed 3D-controllable StyleGAN enables explicit pose control over portrait generation. This distillation allows direct compatibility between 3D control and many StyleGAN-based techniques (e.g., inversion and stylization), and also brings an advantage in terms of computational resources.
TL;DR We present a novel 3D-aware GAN, i.e., SURF-GAN, which is able to disentangle and control semantic attributes and then make StyleGAN 3D controllable by injecting the prior of SURF-GAN.We propose a novel 3D-aware GAN, i.e., SURF-GAN, which can discover semantic attributes by learning layer-wise subspace in INR NeRF-based generator in an unsupervised manner.
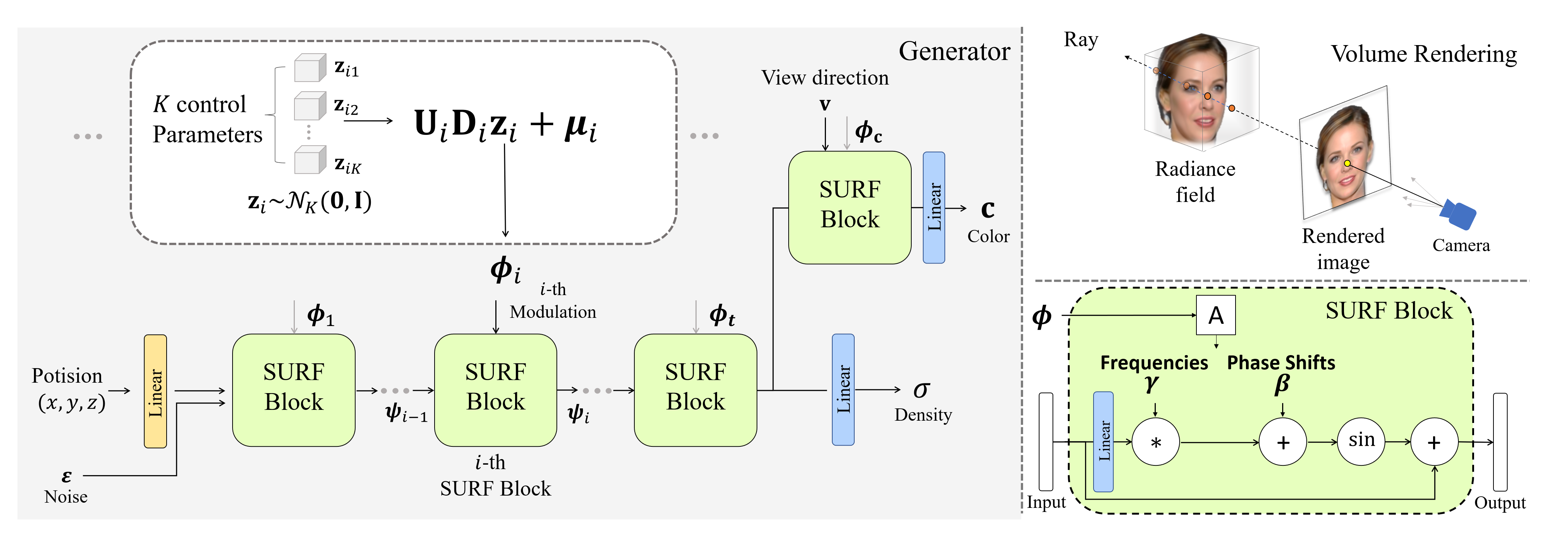


After that, we inject 3D prior from a low-resolution 3D-Aware GAN (SURF-GAN) into a high-resolution 2D GAN (StyleGAN).



@inproceedings{kwak2022injecting,
title={Injecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait Image Synthesis},
author={Kwak, Jeong-gi and Li, Yuanming and Yoon, Dongsik and Kim, Donghyeon and Han, David and Ko, Hanseok},
booktitle={European Conference on Computer Vision},
pages={236--253},
year={2022},
organization={Springer}
}
