
|
Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual
Try-On and Try-Off
Seungyong Lee*, Jeong-gi Kwak*
ACM SIGGRAPH Asia, 2025
paper |
project page |
demo
|
|
|
ViVid-1-to-3: Novel View Synthesis with Video Diffusion Models
Jeong-gi Kwak*, Erqun Dong*, Yuhe Jin, Hanseok Ko, Shweta Mahajan, Kwang Moo Yi
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Highlight (Top 10%)
paper |
code |
project page
|
|
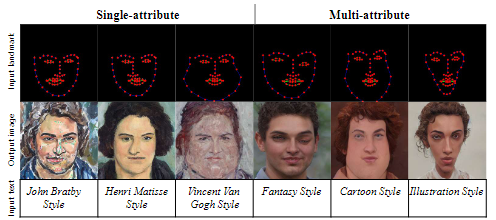
Towards Multi-domain Face Landmark Detection with Synthetic Data from Diffusion Model
Yuanming Li, Gwantae Kim, Jeong-gi Kwak, Bonhwa Ku, Hanseok Ko
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
paper
|
|
|
Injecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait
Image Synthesis
Jeong-gi Kwak, Yuanming Li, Dongsik Yoon, Donghyeon Kim, David Han, Hanseok Ko
European Conference on Computer Vision (ECCV), 2022
ETNews ICT Paper Awards sponsored by MSIT Korea
paper |
code |
project page
|

|
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Dongsik Yoon, Jeong-gi Kwak, Yuanming Li, David Han, Hanseok Ko
IEEE International Conference on Image Processing (ICIP), 2022
paper
|

|
Generate and Edit Your Own Character in a Canonical View
Jeong-gi Kwak, Yuanming Li, Dongsik Yoon, David Han, Hanseok Ko
IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2022
paper |
poster
|

|
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Jeong-gi Kwak, Youngsaeng Jin, Yuanming Li, Dongsik Yoon, Donghyeon Kim, Hanseok Ko
British Machine Vision Conference (BMVC), 2021
paper |
code
|

|
Reference Guided Image Inpainting using Facial Attributes
Dongsik Yoon, Jeong-gi Kwak, Yuanming Li, David Han, Youngsaeng Jin, Hanseok Ko
British Machine Vision Conference (BMVC), 2021
paper |
code
|

|
CAFE-GAN: Arbitrary Face Attribute Editing with Complementary Attention Feature
Jeong-gi Kwak, David K. Han, Hanseok Ko
European Conference on Computer Vision (ECCV), 2020
paper
|


